Since December of 2023, I built a system to record every trade in the entire stock market from Polygon.io’s feed. I have been using this in conjunction with timescaledb to create bars for the various intervals for my trading and research systems.
The Problem
The system has been working great, but there has been one concern: Storage. I use a dedicated server with 2x 8TB NVMe SSDs (RAID 1) to power this operation, a large quantity but not infinite. Nearing the 1 year mark, we were using over 3TB, meaning by the end of 2025, it would be exhuasted.
One solution would be to buy more storage, the server could theoretically support another 2x 8TB SSDs, which could give us 16TB usable, or even 24TB if we risked RAID 5. The problem is that only adds a few years to the equation, and Postgres actually has a hard limit, 32 TB. Even if I were to migrate some of the data to my HDD server, we can’t cross 32 TB.
Now from first glance, 3.1 TB of numerical data might seem absurd, but how much is it really? First of all, how many trades do we have?
From running a simple query, we have around 15.5B rows, knowing that 3.1TIB is 3.1* 1024^5, or around 3.5 Trillion bytes, against 15.5 Billion rows, that leads to a ratio of 225 bytes per row, that’s our number to beat.
Comparing various formats
Now that we know we have a problem, lets start thinking about solutions.
Build a custom database / Migrate to an efficient data store
The first idea I had was similar to what led to the creation of Tectonic (& then seismicDB) in the first place, build a new database. SeismicDB, an efficient level 2 database shows an example of how much more efficient a binary data store can be.
In fact, I had already begun work on making SeismicDB more usable in a stock (where we may not know every ticker that we will be recording) scenario, by allowing auto creation of DBs for an unseen ticker. Still, I would need to add substantially more metadata, and given I’m not tracking level 2, it seems more logical to create a separate format.

For reference, this is the data in each row, the names are simply derived from Polygon.io’s documentation. The first obivous optimization is to store the symbol somewhere else, and instead use a number to mark the symbol. We can also store this per file, rather than per row.
The other key optimization is using a 32 bit offset from the start of the file (1 file per sym per day) instead of storing the 64 bit milisecond offset on every row.
The main challenge is the conditions array. Given this array has over 200 possible outcomes, and on average only has a few (but can have many), there’s no obvious efficient implementation. I ultimately went with bincoding a rust vector of the conditions, which worked out ok.
The alternative would be to create a bit array of 255 bits, which is larger on average. Perhaps a dynamic bit vector could be a solution?
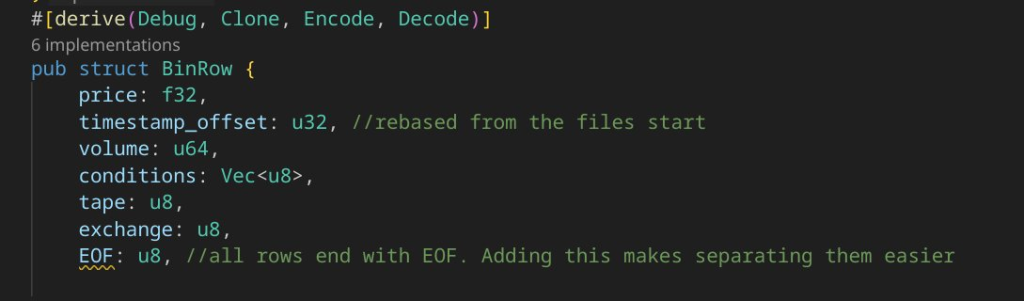
Ultimately the binary implementation ends up being dramatically more efficient, coming in at 29 bytes / row. Not bad, but building the same level of infrastructure to query it would be a substantial effort.
Naive CSV
Similar to how any trading strategy should be benchmarked against “the market”, any storage strategy should be benchmarked against raw CSV data. CSV files simply take the rows, put a comma in between them and call it a day. The CSV file comes in at 1.1TB for the database, roughly 2/3 smaller than PostgreSQL (~80 bytes / row).
While CSV is simpler than a custom binary format, it ends up being no easier to work with, and as a result isn’t a serious contender relative to binary formats.
Compression
Another option, popular with data vendors is to compress the data, often with the zstd format developed by meta. Why didn’t I think of that? Well, the main drawback of compression for recording a live feed is how it works, and it’s lack of appendability.

Unlike lossy compression that might be used for media files, data compression works by analyzing the entire dataset (or file) and as a result, a ZSTD compressed file cannot be modified without re-doing the whole thing. With all of that aside, how well does it work?

ZSTD compression reduced the size of our CSV by 80%, and the binary format by an additional 66%. Wow, that’s dramatic, we’re in the neighborhood of teen bytes per row, and it could get better still, considering columnar data stores.
TimescaleDB Compression
I’d already mentioned that the base database is stored in PostgresQL with the TimescaleDB extension, so why weren’t we just using that? Well I’d actually tried it, and initially had very poor results, actually doubling the filesize.
The killer mistake: The segmentby option. Initially I had enabled this across many columns leading to an explosion in filesize, but that is suboptimal. Ideally you use few or no segmentbys.
For my second attempt, I only segmented by the symbol, and we had immediate success. From 3.2TB to 300GB, or a 92% decrease in filesize, while keeping all of the SQL features and database we use.
This was an amazing result, and ultimately the option that makes the most sense in my opinion. Timescale’s compression works by using a hybrid database, where the new data is stored in a regular row database, and the old (compressed) data is moved to a columnar store.
We get to have our cake and eat it too, getting the benefits of a columnar database with fast append support.
Conclusion
The ultimate comparison is as follows.
| Database | Storage Size for 100 GB of CSV Data | |
| TimescaleDB (Default) | 300GB | |
| CSV | 100GB | |
| Shinoji Research Custom Bincode Format | 39.5GB | |
| CSV Compressed with ZST | 20 GB | |
| TimescaleDB (Compressed) | 19.5 GB | |
| Bincode DB with ZST | 9.45 GB |
While bincode with ZST remains more efficient, the complexity of implementing it makes sticking with Timescale & PostgreSQL the preferred option for now. If I were to start ingesting level 2 data, those needs may change, but PostgreSQL + TimescaleDB is absolutely capable of handling financial timeseries needs.
I might also test the Bincode DB in columnar format for a theoretical “best possible” compression.
Leave a Reply