In this article I will attempt to benchmark the mathematical performance of PyO3, & pure python 2 ways using an approximation of the following function for computing pi (substituting infinity with a chosen number).
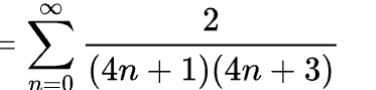
First of all we will create a function in Pure Python & Pure Rust, then we can do 2 integrations. First of a PyO3 function that will run the entire loop (essentially identical to the rust implementation), given x runs.
A second function will only compute iterv = (2.00/((4.00*n +1.00)* (4.00*n+ 3.00))) in rust & run the loop in python. My interest here is to determine whether the IO performance of PyO3 is appropriate enough to build a hybrid Python-Rust quant trading system.
First the Python Implmentation
n = 0.00
s = 0.00
iterv = 0.00
runs = 100000000.00
s = 0.00
while n < runs:
iterv = (2.00/((4.00*n +1.00)* (4.00*n+ 3.00)))
s = s + iterv
n = n +1.00
print(s*4)
next in rust we can do
fn main() {
let mut n = 0.00;
let mut s = 0.00;
let mut iterv: f64;
let mut runs = 100000000.00;
let mut s = 0.00;
while n < runs {
iterv = (2.00/((4.00*n +1.00)* (4.00*n+ 3.00)));
s = s + iterv;
n = n +1.00;
}
println!("{}", s*4.00);
}

Both programs output the same approximation, I created the python code by copy & pasting the rust & removing the let (declarations), removing semicolons & replacing { with :. The rust algorithm is a LOT faster (0.12s vs 12s), which should surprise nobody. Given startup time, we’d actually need to run more iterations to get a good estimate of the Rust program’s true speed, I choose 100,000,000 iterations to have the Python example fast enough.
Programming the PI approximation
I’m more concerned with the IO (python -> rust) speed than the accuracy of the calculation, for convenience I am going to use F64s & floats, which you should absolutely not do if you’re intending to calculate pi precisely.
Using Pyo3 To accelerate the math
fn calculate_pi_n_approx(runs: f64) -> PyResult<f64> {
let mut n = 0.00;
let mut s = 0.00;
let mut iterv: f64;
let mut s = 0.00;
while n < runs {
iterv = (2.00/((4.00*n +1.00)* (4.00*n+ 3.00)));
s = s + iterv;
n = n +1.00;
}
Ok(s)
}
#[pyfunction]
fn do_pi_iter(n: f64) -> PyResult<f64> {
let iterv;
iterv = (2.00/((4.00*n +1.00)* (4.00*n+ 3.00)));
Ok(iterv)
}PyO3 has a fairly straightforward structure, I copied most of this from the documentation & adjusted to my needs. The results are below, what I was most curious about was how PyO3’s variable passing (for lack of a better term) would perform.
| Method | Runtime | Runs Per Second | Relative Performance |
| Python | 12.05 | 8298755.19 | 1.0 |
| Algorithm in PyO3 | 0.4 | 250000000 | 30.125 |
| Loop in Python, math in rust | 71 | 1408450.7 | 0.1679 |
| Loop in python, math in rust (Added the s recursion to the rust part) | 75 | 1333333.33 | 0.160666 |
| Pure Rust | 0.12 | 833333333 | 100.41 |
| Pure Rust(1 billion iterations) | 1.0 | 1000000000 | 120.5 |
| PyO3 1 billion | 3.76 | 265957447 | 32 |
The answer is that for this type of calculation, you are obviously better off writing the whole thing in either language, but the runs per second of the inefficient pass approach is still very impressive at over 1.4m runs / second (0.7 μs / pass). If you have a formula that takes more than 0.7μs in python to compute, offloading via this method may make sense, but I would always recommend checking for relevant libraries first.
Not Reinventing the wheel
It’s always a good idea to see if you can use libraries before writing your own, in the math & statistics domain SciPy, NumPy, Pandas & newcomer Polars (actually built with PyO3) are all very relevant. While you need to be careful, you can get a rough translation of code using chatGPT (with GPT 4.0 mode).
As an example, using numpy instead of Python’s built in math operators, we can compute the same series up to 100m & have it complete in 0.02s, adding another 0 however raises the execution time to 4.6s (slower than rust or PyO3).
The reason for this is parallelization, the numpy implementation creates an array & computes all 100,000,000 terms at once & then adds them up. This is far faster than any single threaded for loop approach. The limitation is that you need enough memory to every iterv, instead of doing it one by one.

If we wanted to run more than 1 billion on this 32gb ram MacBook Pro, we would need to use a different method.
import numpy as np
def compute_series(num_terms):
# Generate an array of 'n' values
n = np.arange(num_terms)
# Calculate the terms all at once
terms = 2.0 / ((4.0 * n + 1.0) * (4.0 * n + 3.0))
# Sum the terms
total = np.sum(terms)
return total
def main():
runs = 1000_000_000
result = compute_series(runs)
print(result * 4)
if __name__ == "__main__":
main()
Conclusion
I hope this open experiment was interesting to read. If you are familiar with both Python & rust, a hybrid approach may be valuable when you have reusable computationally intensive functions, and also want the flexibility of a python environment.
Leave a Reply